Summary
I’m pleased to report that I’ve completed another 365 days of walking in 2023, covering a grand total of 1,766km, which is the equivalent of walking to the northern coast of Iceland or as far as Gibraltar near Spain, or to Bratislava in Slovakia or to Stockholm in Sweden.
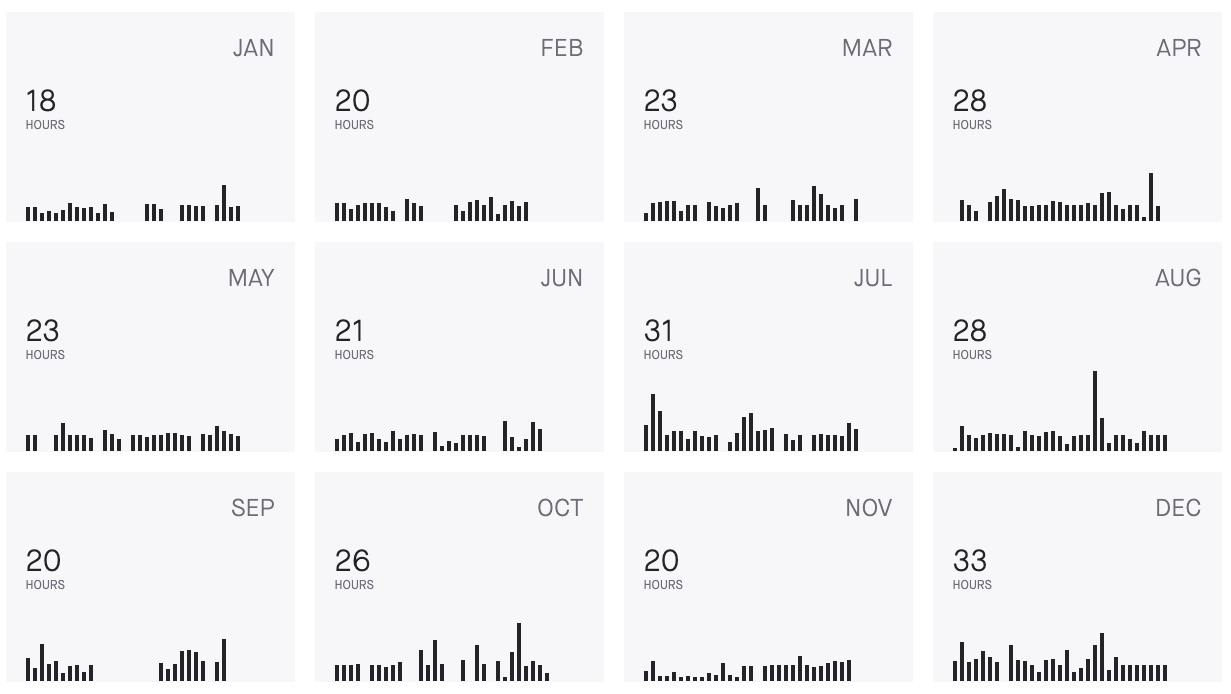
In total, I spent 291 hours walking the equivalent of 42 marathons (one every 8.5 days or so), which equates to an average of 4.84km per day, or 34km per week, or 147km per month.

This was a continuation of a journey that began in 2022 (see You’ll Never Walk Alone: Reflections of 365 Days of Walking) but with a slightly different (but no less satisfying or motivating) format which I’ve detailed below. I hope you enjoy reading it as much as I enjoyed walking it!
New Year, New Goal
Having walked 5km every single day of 2022, I began 2023 with an open mind about doing the same again. However, due to a combination of bad weather, unfortunate timing and family logistics, I finally broke my streak on 14 January 2023 – a streak that had lasted a whopping 378 days!
While I secretly knew this would eventually happen (walking 5km every single day is ultimately not sustainable because it can mean walking in very wet weather just for the sake of saying you took a walk, which was sometimes demoralising rather than motivating), I was still pretty devastated when it did happen. I took a complete break for several days to mull things over.
With the help of a long-time work colleague (Craig Brookes), who is an avid cyclist and who I’d been sharing my walking escapades with, I managed to find a way to accept and recover from the disappointment of breaking my streak.
Craig astutely pointed out that what I actually achieved in 2022 was to meet a goal that I’d set for myself (where the goal was to “walk 5km every single day”). Craig’s advice was to pick a different goal – one that was equally challenging (and healthy) but which did not bind me to walking every single day – and set about meeting that one instead.
That’s exactly what I did and I duly set a new goal to walk 1,500km over the year which worked out at 125km per month, or around 29km per week.
Activity Tracking
Another recommendation from Craig Brookes was to use the Strava app to track progress toward my goal. While I could have chosen any number of other activity tracking solutions, I took Craig’s recommendation in good faith and it did not let me down.
It added minimal overhead to my walks (where I merely needed to start and stop the app at the beginning and end of each walk), tracked both the distances and durations, along with the shoes worn and allowed me to enter a brief description of each walk which I decided to do also.
All of this functionality was available on the free edition, too, which was a welcome bonus.
Equipment
In my view, walking requires little or no investment in specialist equipment. My essentials are:
- Shoes: Any decent walking shoes will suffice but I chose Nike Pegasus 40 because they give me the option to try jogging from time to time as well (trust me: you do not want to try jogging in walking shoes, as you’ll learn shortly).
- Earphones: I use Samsung Galaxy Buds and they’ve been brilliant – really comfortable with no protruding parts, terrific sound and really excellent battery life (one week, easily).
- Spotify (or equivalent): Any source of music or podcasts will suffice, but I personally could not walk without listening to something as I’d get bored too quickly.
- Weather Tracker: Doing anything outdoors in Ireland requires careful planning around the weather. I used the RTE Weather service to plan the optimum time (day or night) to avoid the wind and rain, and after two years of using it, I’m very, very confident in its accuracy.
Apart from this, a decent jacket and hat during winter and some breathable t-shirts and shorts during summer should set you up for success.
Diet
I didn’t really (have to) make any wholesale changes to my diet because of my walking routine, but I definitely noticed the impact (or not) of different kinds of food and the impact of my meal times.
For example, if I went for a walk shortly before lunchtime (having not eaten a lunch), I’d definitely feel the effects of that half-way around, and would struggle a little on the way home. In terms of foods I felt gave more energy, pasta and porridge were top of the list, that I recall.
Taking a drink afterwards is super important too, I learned, as you can easily become dehydrated in the hours and days that follow, which can cause other side effects.
My first sports injury
Some time in late autumn, as the very hot weather had abated and I was really enjoying the levels of fitness I was feeling, I became curious about what it might take to try some jogging (as a natural evolution of walking).
I knew that doing so in tiny bursts (e.g. walk for 400m, jog for 100m) was the right way to start, but I overlooked two very important other factors:
- You cannot jog in walking shoes – they’re simply not designed to absorb the levels of shock involved in jogging.
- As a beginner, your jogging stride needs to land on the balls of your feet, not your heels.
I paid a very heavy price for overlooking these and was out of action for 9 days, needing a doctor’s visit followed by physiotherapy to recover fully. You live and you learn, right?
The Weather
Like in 2022, the weather was an important factor in my 2023 journey. As above, I relied heavily on the RTE Weather service to plan the best times for a dry walk, or to accept that I would not be able to walk at all. I also think that 2023 was a much wetter year than 2022, because I missed around 20 walks due to rain in 2023, whereas I seem to recall walking in heavy rain just 5 times in 2022.

That being said, the majority of other kinds of weather, which included sunshine, warmth, starry nights, full moons, crisp cold, high and low tides, provided no shortage of unique moments to remember fondly, for all sorts of different reasons.
Wellbeing
I’m very happy to say that I’ve continued to develop and discover my own flavour of wellbeing as a result of walking regularly. It remains rooted in knowing that doing so is ultimately good for me, but also extends to a sense of accomplishment (for having met the goals I set for myself) as well as numerous emotions that evoke senses of happiness, sadness, reflectiveness and gratitude about a wide range of topics.

In many ways, I feel that my walks have turned into a form of “me time”, which I happen to spend while taking some exercise in parallel. The time is mostly spent listening to podcasts or music, but is sometimes spent getting lost in your own thoughts (about life and/or people past and present), all of which ultimately feels good for the soul and leaves you feeling quite energised.
Entertainment
I definitely listened to more podcasts than music in 2023.
Musically, I circled around some of the back catalogues of Van Halen, Queen, Bruce Springsteen, U2, The Smiths, and even some ABBA (their songs actually have nice, regular beats well suited to walking) and Harry Styles, while rediscovering the genius that is John Willams (several times), plus numerous classical offerings which I find quite relaxing and uplifting.
In terms of podcasts in 2023, these ones are now my regulars (in order of frequency/popularity):
- The 2 Johnnies – probably still my favourite
- The Rest is Football (with Gary Lineker, Alan Shearer and Micah Richards)
- RTE Documentary on One
- The Gary Neville Podcast
- Sky Sports Football
- Sky Sports F1
- Crime World (by Sunday World journalist, Nicola Tallant)

While I don’t listen to as many episodes as I used to, the Documentary on One series from RTE remains a treasure trove of fascinating stories, as uplifting as they are sad and as educating as they are enlightening. Crime World is OK (but only OK) and I found the episodes a little repetitive after a while. I’m sure others may feel similar about sport, but that’s just my take on it.
By the numbers
I’ll finish with a few statistics for the other data nerds like myself, most of which I gleaned from Strava but some of which I took from a homegrown spreadsheet that I used to complement Strava:
- Totals
- Total Distance Walked: 1,765km
- Total Time Walking: 291 hours
- Total Number of Walks: 383
- Number of Days Missed / Walked: 53 (15%) / 312 (85%)
- Longest
- Longest Distance Walked in a Day: 14.3km (September)
- Longest Distance Walked in a Week: 53.9km (December)
- Longest Distance Walked in a Month: 206.4km (December)
- Longest Distance Walked in 7 consecutive days: 63.2km (December)
- Longest Walking Streak: 48 days (July – September)
- Averages
- Average Distance Per Day: 4.84km
- Average Distance Per Week: 34.4km
- Average Distance Per Month: 139.2km
Revised Goals
My original goal of 1,500km only required me to walk an average of 4.1km per day. However, as my regular route (to and from Tramore Promenade) was closer to 5.2km, I actually met my original goal in mid-November and was on target to surpass the original by around 200km.

I therefore decided to set a revised target of 1,750km to see how I’d fare. This took a little more perseverance towards the end but was ultimately achievable in the time available.
Even in the final week of the year, I realised that I could reach 200km in a single month, so I tweaked the revised goal once more and ended up surpassing that by a small margin too, all without too much effort.
Final Reflections, in a Word (Cloud)
As I mentioned earlier, I took the liberty of entering short descriptions for each walk into Strava. I didn’t have any particular reason for doing this back in January but did feel that one might present itself as the days and weeks passed by, and so it did.

This Word Cloud was generated from the descriptions I entered in Strava and, on reflection, I think it’s a pretty accurate visualisation of what I remember as the prominent elements of my year of walking.
Until next time…
You’ll Never Walk Alone!