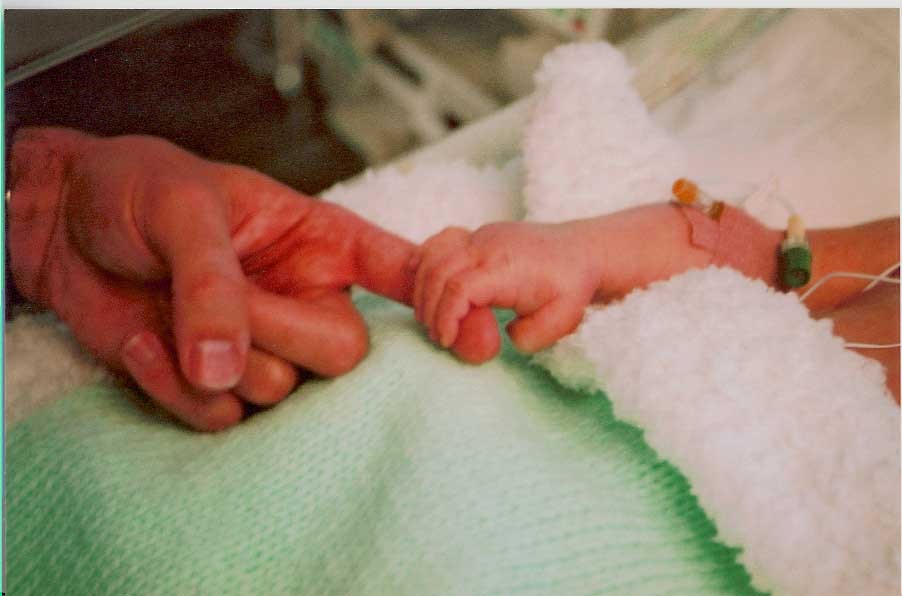
As I reflect on the 18 years that have passed since I first became a father (on this very day in 2002), I do so with incredibly mixed emotions and a deep sense of anguish that we cannot share the occasion with our beautiful son, Jake, who left our world after just 9 days, on Friday, 25 October 2002.
However, while there’s not a day that goes by that we don’t think of him and we yearn to hold him in our arms just one more time, we are comforted (and often surprised) by the things that his short life has taught us in the years since his passing, and I thought it might be nice (and potentially helpful to others) to share some of those lessons today in his honour.
Life is not over – it’s just very, very different
The loss of a child is something you will never, ever “get over” but it is something that you can learn to accept and live with, with the passage of time, while experiencing some enormously uplifting moments along the way. Not only will these moments keep you firmly grounded in life, but they can also serve to inspire the best in yourself and in others, in ways that may otherwise not have been possible.
Some of these moments that I recall and that I hold dear to my heart include beautiful remembrance ceremonies and anniversary Masses at Crumlin Hospital, Dublin, receiving a posthumous bravery certificate from the Irish Heart Foundation (our son underwent heart surgery less than 24 hours after his birth) and a Roll of Honour certificate from the Irish Kidney Association (I am proud to say my son was also an organ donor).
Our annual, overnight trip to Dublin to mark his anniversary has also become an extended family tradition which our other children and their cousins now hail as one of the highlights of their year.
The Japanese Maple tree that stands proudly at the bottom of our garden is also a constant, warming, living, breathing reminder of his place in our family unit. Be it the smile it puts on your face while cutting the grass or the happy sounds of your children playing nearby, or even seeing your own Father stand in silent prayer there at random moments throughout the year, these are all uplifting experiences that you learn to love dearly, and that enrich your now very different life.
Find the positives where you can – they do exist
A close friend of mine, with some personal experience in this area, was brave enough to say this to me a few days before Jake died and it took me several years to learn what it truly meant, and to accept how true it is. That is because, no matter how far you travel in life and how sorry you may feel for yourself because of what happened to you on that life journey, you will learn (several times over) that there is always someone less fortunate than you are, with no exceptions.
We were blessed with a perfect pregnancy, photographs and videos of our newborn son, living and breathing. We got to hold him, to smell him, to hug him and kiss him, multiple times over. Some of our extended family members got to meet him too, if only for a brief moment, and so we have memories, real memories.
Sadly, we have met many people that experienced a similar loss to ours, but with none of the memories we have to cherish. Oddly, we count our blessings for this.
Material things simply don’t matter – family is what matters
I like my home comforts, gadgets, cars and other material possessions as much as the next person, but I definitely find them far less important in my life on foot of the experiences of 18 years ago. Others I’ve met have conceded feeling the same way over time.
I don’t dwell on this and it’s not a major discussion point in my life, but I definitely find myself less motivated to spend time with (or on) material items. I guess it’s because these things are ultimately replaceable, if you know where to find them at the right price, which makes them ultimately less valuable in a human context.
However, the things that I now find most happiness, motivation and contentment in actually cost nothing. They are spending time with family, creating life memories for (and with) our children, but with a far deeper appreciation for why they are so important, valuable and irreplaceable.
We are therefore so especially proud of our first-born son, Jake, today for teaching us all so much about the truly important things in life, in his own special way.
Happy Birthday, son, and thank you!